次年2月,他们就获得了来自星火资本(Spark Capital)和经纬创投(Matrix Patners)的1100万美元A轮融资。
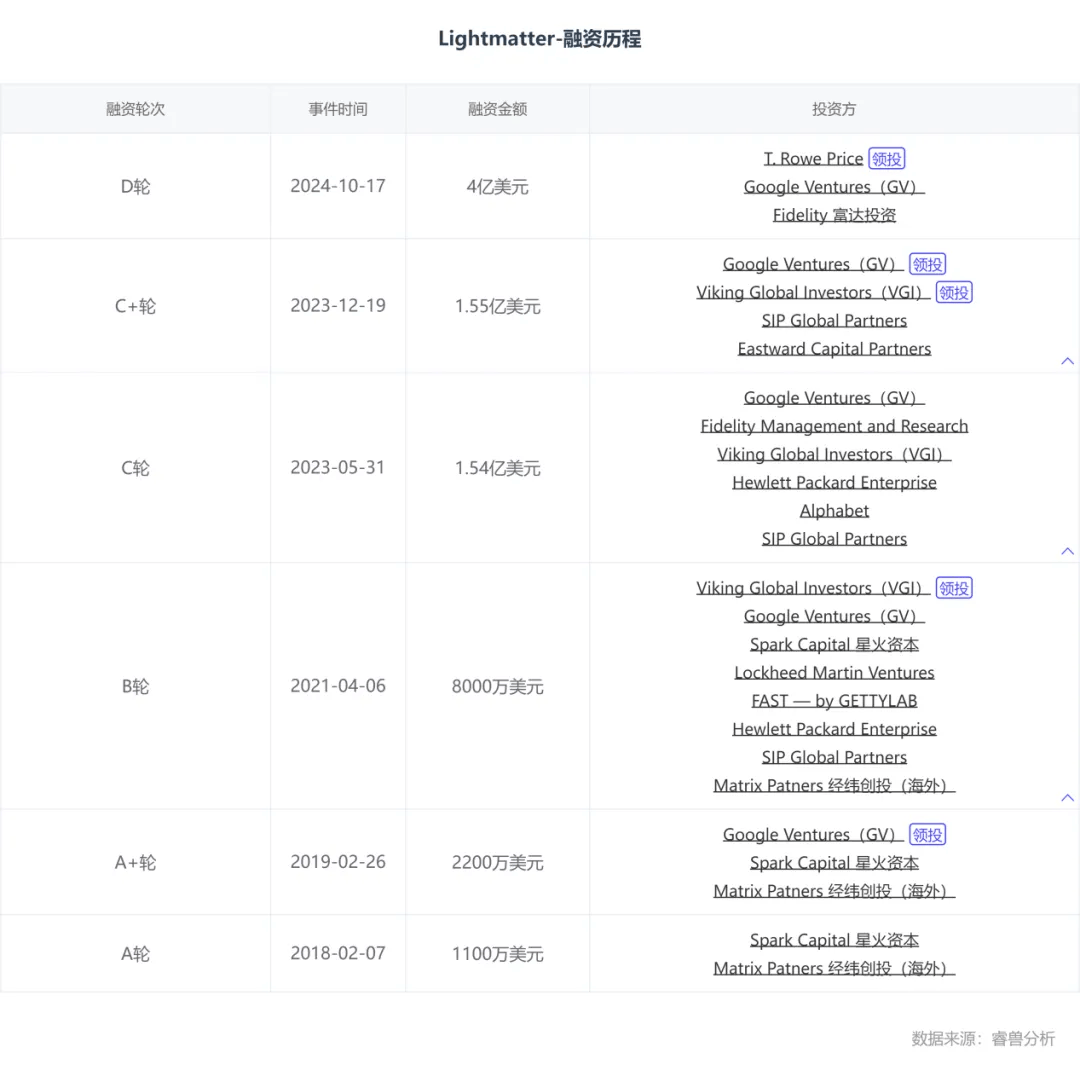
此后便一发不可收拾,睿兽分析显示,Lightmatter共完成6轮融资,其中谷歌风投(Google Ventures,GV)已经从A+轮连投五轮,星火资本(Spark Capital)和经纬创投(Matrix Patners)也都连投了三轮。
值得注意的是,2023年12月,Lightmatter宣布完成1.55亿美元(约合28.5亿元人民币)C+轮融资,公司估值超过12亿美元(约合85.6亿元人民币),正式跻身独角兽。近日,公司更是获得了4亿美元(约合28.5亿元人民币)D轮融资,成为其有史以来最大一轮融资,估值达到44亿美元(约合313.7亿元人民币),累计融资8.22亿美元(约合58.6亿元人民币)。

“把电换成光”正成为一场算力革命
实际上,在AI革命背后,“把电换成光”正在成为一场芯片行业的潜在算力革命。
AI带来的巨大计算需求正在推动数据中心的发展,不过并不是直接插入一千个GPU那么简单就能解决。
这其中,互连层是将 CPU 和 GPU 机架变成一台巨型机器的关键。因此,互连速度越快,数据中心的速度就越快。
随着摩尔定律接近极限,未来算力提升的空间很有可能在光子计算芯片技术上。数字芯片受限于底层元器件:CMOS晶体管,而光学信号和光学器件遵循不同的物理原理。
和传统芯片不同,光芯片是通过光学技术而非电信号实现信息处理。而依靠光作为传递载体,让光芯片拥有了更高的传输速度、更低的功耗、更大的带宽。
经过测算,理想状态下,光芯片的端到端功耗仅仅为电子芯片的10%,延迟只有其1%,而同等条件下的算力却能达到电芯片的100倍以上。
从下游趋势而言,随着生成式AI将海量的高质量数据、大规模参数的模型推向市场,针对于大模型算力芯片的需求已达到非常高的水平,并仍在快速增长。这对未来的AI算力芯片提出了大算力、低功耗且成本可控的需求,而这些需求也恰好是光芯片的优势所在。
Lightmatter想要做的正是提升GPU或CPU芯片互联层的效率,从而突破现代数据中心的瓶颈。通过光子技术,可以让数百个GPU同步工作,从而简化复杂又极其烧钱的AI模型训练。
Lightmatter一直在开发的光子芯片,构建了速度最快的互连层。
Nicholas Harris指出,“针对超大规模的数据中心,如果他们想要一台拥有一百万个节点的计算机,无法使用思科传统交换机来实现。一旦离开机架,高密度互连就变成了一根绳子上的杯子。”
因此,对于一百万个 GPU,你需要多层交换机,这会增加巨大的延迟负担,Nicholas Harris说。
“你必须从电到光再到电再到光……你使用的电量和等待的时间都是巨大的。而且在更大的集群中,情况会变得更糟。”
那么,Lightmatter又是怎么做的呢?
其首款产品Envise是一款专门用于人工智能操作的芯片,另一款产品Passage则促进芯片之间数据传输的互连,它们利用光子和电子来提高操作效率。

Envise是一种通用机器学习加速器,,结合了光子学和基于晶体管的系统
此外,Lightmatter还研发了世界上第一个3D堆叠光子引擎Passage,能够在超大规模数据中心以光速连接数千到数百万个处理器,用于最先进的人工智能和高性能计算工作负载。
具体来说,Passage提供了一个功能类似于OCS(光路交换机)的通信层,该层位于基本和ASIC之间,几乎可以实现全方位通信,这个通信层可以进行动态的配置。通过采用硅内置光学(或光子)互连的形式,使其硬件能够直接与GPU等硅芯片上的晶体管连接,这使得在芯片之间传输数据的带宽是普通带宽的100倍。

Passage是晶圆级可编程光子互连,使异构芯片阵列能够进行通信




